
본문은 [웹 프로그래머를 위한 데이터베이스를 지탱하는 기술]를 읽고 간단하게 정리한 글입니다. 필요에 따라 생략/수정된 부분이 있을 수 있으며, 내용이 추후 변경될 수 있습니다.
1. 데이터 모델링 기술의 중요성
- 애플리케이션을 만들 때 중요한 것이 바로 "어떤 데이터 항목이 필요한가"를 제대로 파악하는 것이다
- 애플리케이션 가동 후에 항목(=열)을 추가하는 것은 쉽지 않다
- 기능 추가가 자주 발생하는 애플리케이션에서 데이터 항목을 완벽하게 미리 밝혀내는 것은 불가능하다
- 따라서 데이터 항목을 추가하기 용이한 디자인도 중요하다
2. 예제를 사용하여 생각해 보자
이 장에서는 직원과 소속조직/부서를 취급하는 애플리케이션에서 필요한 데이터 항목을 파악하여 적절하게 테이블 설계에 도입하는 과정을 보여주고자 한다. 애플리케이션의 요구사항은 다음과 같다.
- 직원은 고유의 사원 번호를 가진다.
- 같은 이름의 사원이 있는 경우가 있다.
- 이름의 한자가 다르다 해도 발음이 같은 직원이 있는 경우가 있다. (참고로 원저자가 일본인이다)
- 직원은 메일 주소가 부여된다. 메일 주소는 중복되지 않는다.
- 경력 사원 등 수속 절차에 따라 메일 주소의 부여가 지연될 수 있으며, 이 경우는 당분간 메일 주소가 없는 상태가 된다.
- 직원은 최소한 하나 이상의 부서에 소속된다.
- 부서 이름은 중복될 수 있다.
- 부서 전화번호가 가지각색이므로 이것도 관리하고 싶다.
이러한 요구사항에 필요한 데이터 항목을 나열하고 테이블 설계에 도입해 나가는 작업을 데이터 모델링이라고 한다.
1) 전통적인 방법으로 테이블을 만들어보자
- 테이블은 행과 열로 구성된다
- 직원 테이블의 행엔 각 직원이, 열엔 관리해야 할 항목이 해당된다
- 열은 명사이므로 애플리케이션 요구 사항에서 키워드가 될 것 같은 것들을 모아둔다
- 테이블의 열은 다음과 같이 구성된다
- 사원 번호 (emp_id)
- 사원 이름 (emp_name)
- 사원 로마자 (emp_roman)
- 메일 주소 (emp_email)
- 부서 이름 (dept_name)
- 부서 전화번호 (dept_tel)

- 테이블 설계에선 행을 고유하게 식별하기 위한 식별자를 도입하는 것이 일반적인데, 이를 기본 키(Primary Key)라고 한다
- 그림 3-1처럼 테이블을 설계한 후, 데이터가 쌓이면 중복 값에 대한 문제가 발생하는 것을 확인할 수 있다
- 동일한 문자열을 다시 입력해야 할 수도 있고, 입력 실수가 발생하더라도 확인하기 어렵다

3. 포인트 1: [테이블 관계]를 도입
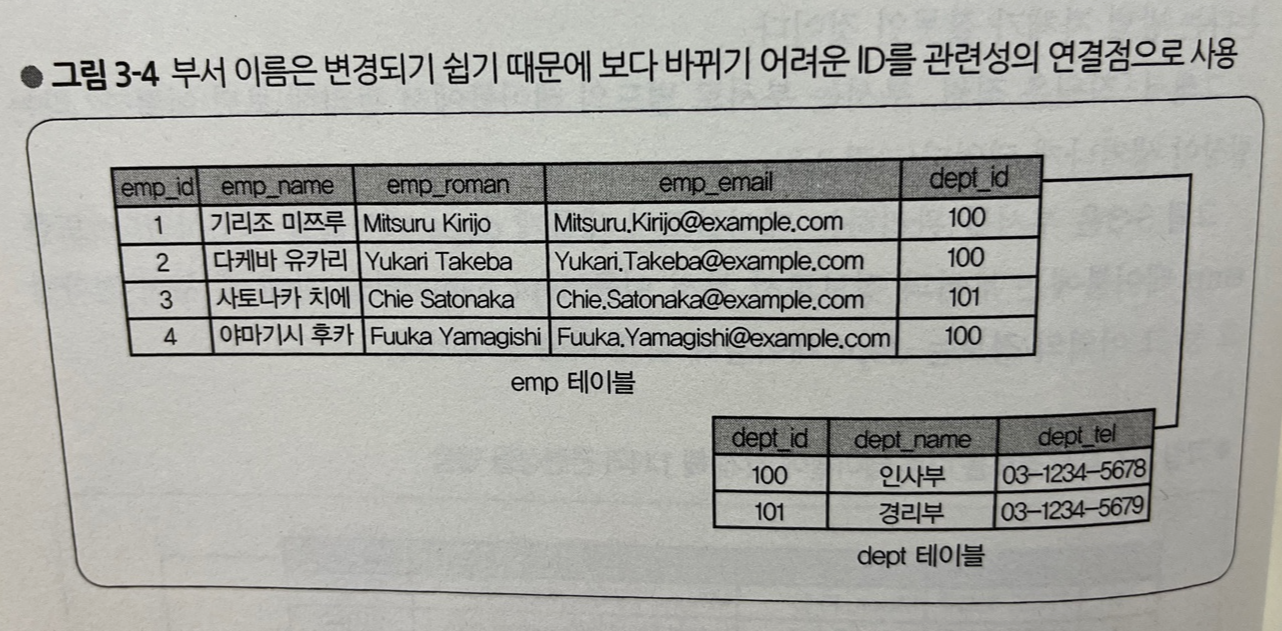
- 그림 3-3은 부서를 관리하는 테이블로서 새롭게 dept 테이블을 도입하였다

- dep 테이블에서 부서 이름(dept_name)은 키가 되고, 이로써 부서 전화번호(dept_tel)가 고유의 값으로 결정된다
- 따라서 여러 직원이 같은 부서에 소속되어 있어도 부서 이름이나 부서 전화번호를 중복해서 등록하지 않아도 된다
- 이는 그림 3-2이 비해 중복 값 문제가 크게 향상되었다고 볼 수 있다
- 그러나 비즈니스적으로 조직 이름이 바뀌는 일이 자주 있으므로 변경되지 않는 ID를 도입하고 그것을 기본 키로 하는 것이 좋다

1) 참조 무결성 제약
- 직원이 소속된 부서 코드가 잘못되지 않았다는 것을 어떻게 보장할 수 있을까?
- 예컨대 부서 코드에 100을 입력해야 하는데 실수로 1000을 입력할 수 있다
- 어느 정도의 실수라면 데이터베이스의 표준 기능인 참조 무결성 제약(Referential Integrity)에 의해 감지할 수 있다
- 개체 무결성 제약(entity integrity constraint): 기본 키에 속해 있는 애트리뷰트는 null 값을 가질 수 없다
- 참조 무결성 제약(referential integrity constraint): 외래 키 값은 null이거나 참조된 릴레이션의 기본 키 값과 동일해야 한다
- 참조 무결성 제약이 적용되면 emp 테이블에 부서 번호를 입력할 때 그 값이 dept 테이블에 있는지에 대한 여부를 자동으로 체크해준다
- 참조 무결성 제약은 데이터의 무결성을 자동으로 관리해준다는 장점이 있다
- 참조 무결성 제약으로 모든 것을 해결할 수 있는 것은 아니다
- 참조의 대상, 즉 부서의 정보 자체를 잘못 입력하는 경우도 존재할 수 있다
- 참조 무결성 제약의 경우 원격 서버에 있는 데이터의 존재 체크를 할 수 없으므로 테이블이 별도 서버로 분리된 경우 적용하기 힘들다
- 이런 경우 애플리케이션 레벨에서의 대처가 필요하다
- 체크 처리의 기본은 "특정 식별자가 관련 테이블에 존재하는지에 대한 여부를 확인"하는 것이다
- 따라서 참조 처리는 매우 고속으로 끝나야 할 필요가 있으며, 대상 열에는 인덱스가 사실상 필수다
4. 포인트 2: 테이블 설계의 타당성 검증하기
그림 3-4와 같이 emp 테이블과 dept 테이블이 분리되었다. 그러나 이렇게 테이블을 구성하더라도 몇 가지 문제가 남아 있다. 예를 들어 "사원이 두 개 이상의 부서에 속할 수 있다(=겸임를 맡을 수 있다)"라는 요구사항이 있을 때, 현재 테이블 구조로선 대응하기 힘들다.
1) 연속적인 번호의 열 도입하기
- 그림 3-4는 emp 테이블에서 부서를 관리하는 열이 한 개밖에 없다
- 따라서 부서1, 부서2, 부서3 등 부서에 대한 열을 여러 개 준비하는 접근 방식이 있을 수 있다
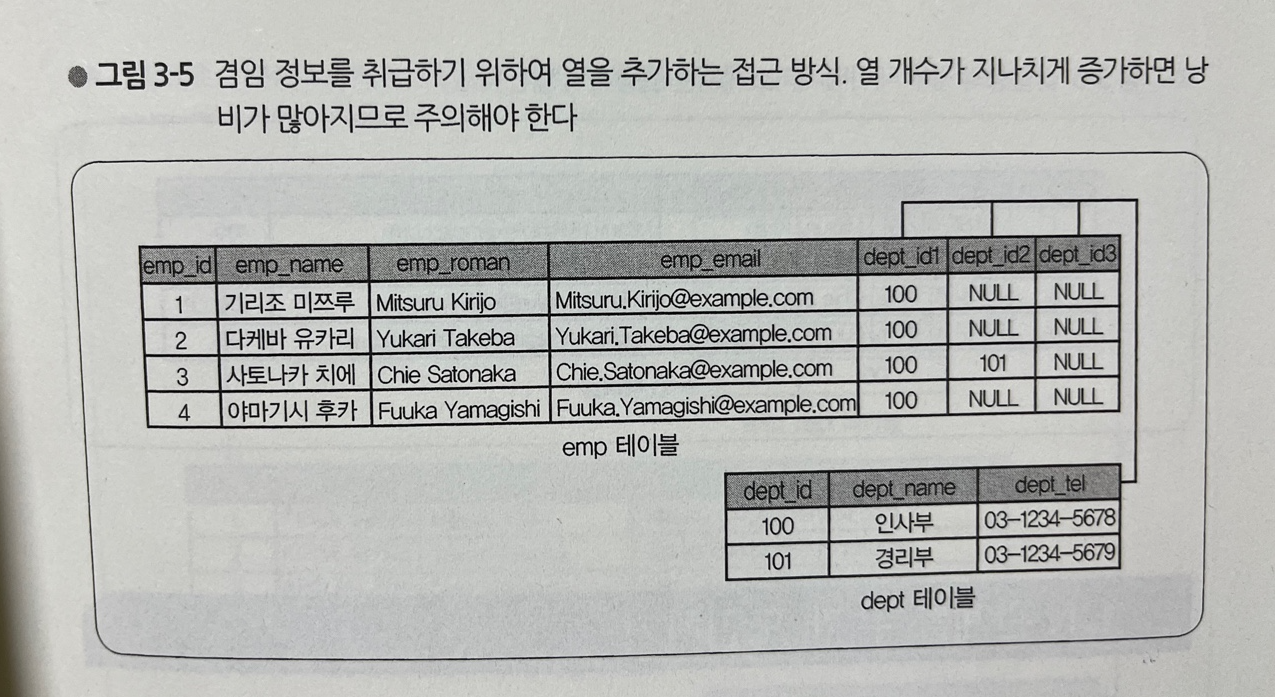
- 열 수가 끊임없이 증가해 나갈 가능성이 있는 경우에는 이 방식은 권장되지 않는다
- 이 경우 물리적인 낭비가 너무 심할 수 있다
- 아무런 열 값이 없더라도 실제로는 NULL이라는 값을 가지고 있어, 물리적인 공간을 소비하고 있기 때문이다 (그림 3-5 참고)
- 마찬가지로 아래의 그림 3-6과 같이 하나의 열(dept_id)에 여러 부서의 정보를 등록하는 것 또한 데이베이스 구현 측면에서 단점이 있다
- dept_id는 정수형이므로 이를 하나의 열에 담기 위해선 SET형이라는 집합형을 도입해야 한다
- 그러나 SET형 자체가 지원되지 않는 데이터베이스도 있고, SET형 자체가 검색 조건으로서(인덱스로서) 사용하기 어려우므로 도입이 어렵다
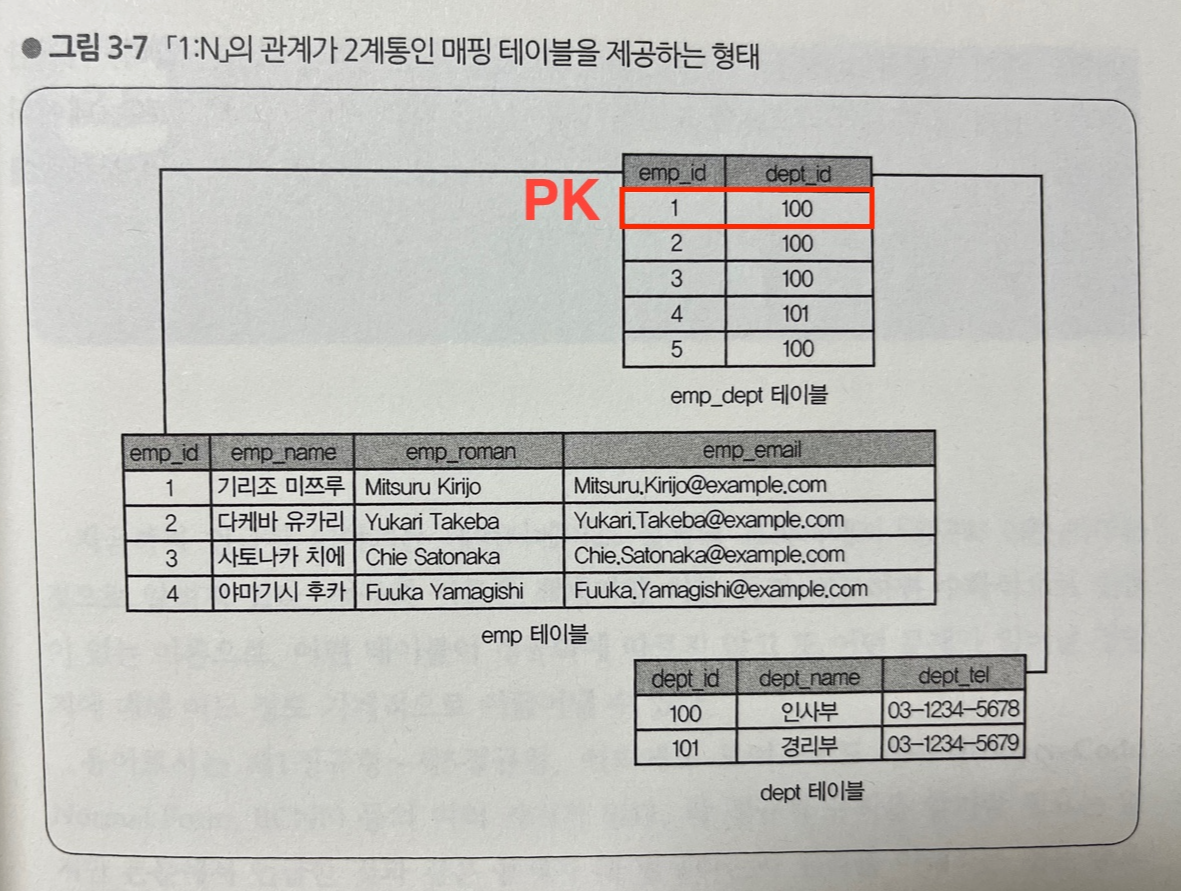
2) 1:N 관계를 두 개 도입하기
- 겸임 정보는 직원 ID와 부서 ID가 정해지면 고유의 의미를 갖게 된다
- 따라서 그림 3-7처럼 두 열을 기본 키로 가진 테이블을 새로 도입할 수 있다
- 이러한 테이블을 일반적으로 매핑 테이블이라고 한다
- 매핑 테이블은 데이터 모델링 과정에서 자주 나온다
- 수십 개에 걸친 테이블을 매핑하는 경우도 있다
매핑 테이블의 특징1 - 기본 키 값이 자주 바뀐다
- 앞서 "기본 키 값은 변경되어서는 안 된다"라는 언급을 한 바 있다
- 하지만 매핑 테이블은 전근 등이 발생했을 때 기본 키 값이 변경된다
- 또는 기존의 열을 지우고 새로운 열을 등록하는 대신 겸임 시작일/종료일 등의 열을 추가하여 기본 키를 변경하지 않는 형태, 즉 항상 추가로 기록해 나가는 형태를 취하는 경우도 많다
매핑 테이블의 특징2 - 레코드 수가 많아진다
- 매핑 테이블의 레코드 수는 매핑의 소스가 되는 두 개(혹은 그 이상)의 테이블보다 많다
- 따라서 데이터의 양이 빠르게 증가한다
- 한 개의 서버로 데이터를 수용할 수 없을 때는 테이블을 분할하여 복수의 데이터베이스 서버에서 데이터를 갖고 있도록 하는 접근 방식이 사용될 수도 있다
5. 정규화 이론의 기본을 파악해 두자
앞서 소개한 예제는 데이터베이스 이론의 정규화에 해당한다. 제1정규형~제5정규형 및 보이스/코드 정규형 등 정규형 규칙을 암기할 필요는 없지만, 본문에서 언급한 문제가 왜 발생하는지 원리를 이해하는 것은 중요하다. 여기에서는 이 장의 예제를 정규화 이론에 적용시켜 설명해 나갈 것이다.
1) 제1정규형
- 테이블 구성에서 중복 또는 반복, 복합값 등을 포함한 구조를 제1정규형이 아닌 테이블이라고 한다
- 그림 3-2, 그림 3-5, 그림 3-6이 여기에 해당한다
- 일관성이 깨지거나(그림 3-2), 열의 중복(그림3-5), 집합형을 취급해야 하는 문제(그림3-6) 등은 애플리케이션에 커다란 부담을 안겨준다
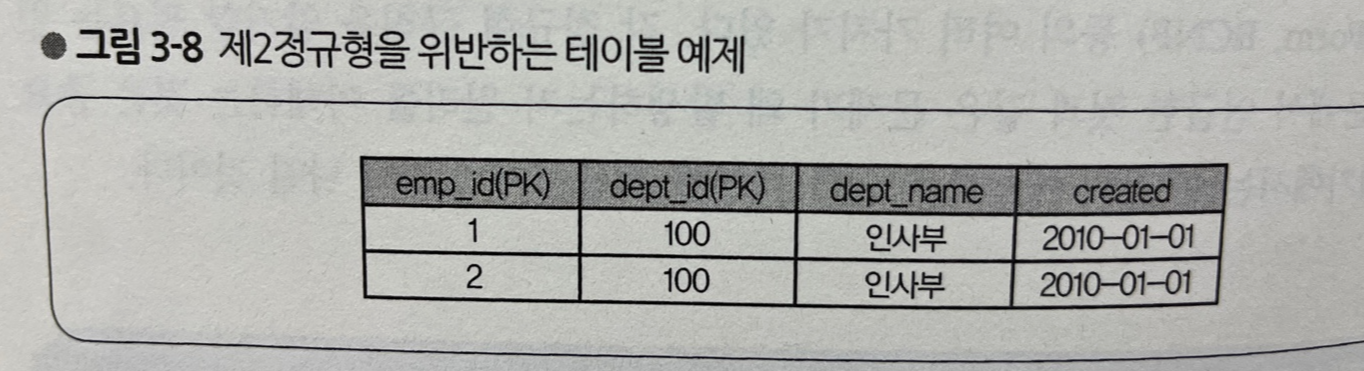
2) 제2정규형
- 이번 예제에선 별도로 설명하지 않았지만, 그림 3-8과 같이 기본 키가 여러 열로 구성되어 있고 그 중 일부 열의 값에 의해서만 결정되는 열이 있는 경우, 해당 테이블을 제2정규형이 아닌 테이블이라고 부른다
- 등록일(created)는 (emp_id, dept_id)의 두 가지 사항을 모르면 특정할 수 없지만, 부서 이름(dept_name)은 dept_id만 정해지면 확인할 수 있으므로 이 테이블에 속하는 것이 적절치 않다
- 즉, 동일 dept_id인데 부서명이 서로 다른 레코드가 등록될 가능성이 있다는(충돌하는) 것이다
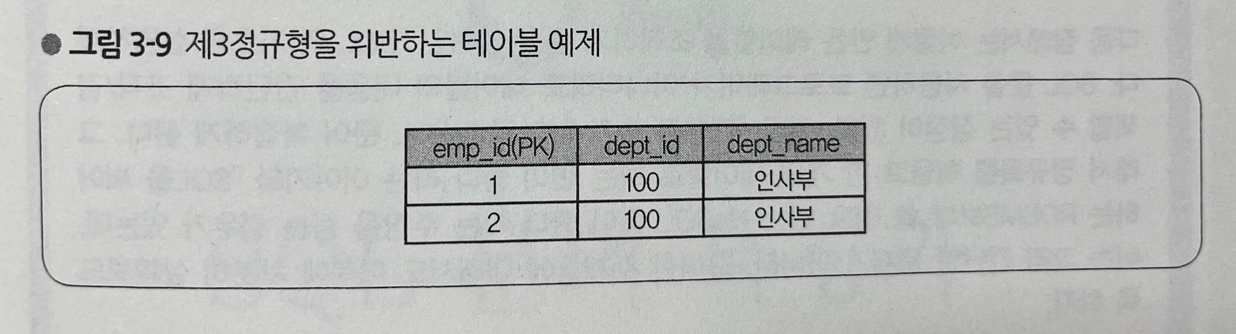
3) 제3정규형
- 원칙적으로 테이블의 모든 열은 기본 키 값에 따라 하나로 결정되어야 한다
- 반대로 기본 키의 열 값이 키본 키가 아닌 열에 의해 결정되는 상태도 문제가 될 수 있으므로 제거해야 한다
- 그렇게 하지 않으면 레코드 간의 일관성이 없는 상태가 되는 등 문제가 될 수 있다
- 그림 3-9를 보면 부서 번호(dept_id)의 경우 기본 키는 아니지만, 부서 이름은 부서 번호에 따라 결정되므로 기본 키의 사원 번호와는 직접 관련이 없다
- 같은 부서 번호임에도 불구하고 다른 dept_name을 등록할 수 있다는 점에서 이것은 문제가 된다
- 이러한 열을 포함하는 테이블 관계를 제3정규형이 아니다라고 말한다
4) 정규형은 어디까지 이해해야 하는가?
- 일반적으로 데이터베이스 이론책으로 학습하는 것은 대부분 제3정규형까지인 경우가 많으므로 "제3정규형이면 충분하다"라는 말을 들은 적이 있는 사람이 많다
- 하지만 이러한 말이 언제나 적용되는 것은 아니다
- 그림 3-4의 테이블은 기본 키가 아닌 열은 모두 기본 키 값이 정해지면 고유의 값으로 결정되므로 제3정규형의 조건을 충족하지만, 현실의 문제를 떠올려봤을 때 겸임할 수 없다는 심각한 문제점이 있었다
- 이는 (emp_id, dept_id)라는 조합을 고려하지 않았기 때문에 발생한 문제였다
- 현업의 데이터베이스 설계에서는 이러한 조합의 결함에 주의하여 테이블 간의 관계를 밝혀내야 한다
- 이를 위해선 어느 정도 테이블 설계에 익숙해지는 수밖에 없다
6. 요약
- 정규화를 하는 것은 중요하다
- 테이블 구조에 따라 업무에 큰 제약을 받게 되는 경우가 존재할 수 있다
'책 > 웹 프로그래머를 위한 데이터베이스를 지탱하는 기술' 카테고리의 다른 글
| [웹 프로그래머를 위한 데이터베이스를 지탱하는 기술] 6장: 트랜잭션과 무결성ㆍ무정지성 (1) | 2023.01.04 |
|---|---|
| [웹 프로그래머를 위한 데이터베이스를 지탱하는 기술] 5장: 데이터베이스는 어떤 때에 크래쉬되는가? (0) | 2022.12.11 |
| [웹 프로그래머를 위한 데이터베이스를 지탱하는 기술] 4장: SQL 문의 특징과 이를 잘 다루는 법 (0) | 2022.12.06 |
| [웹 프로그래머를 위한 데이터베이스를 지탱하는 기술] 2장: 인덱스로 고속 액세스 실현하기 (0) | 2022.11.11 |
| [웹 프로그래머를 위한 데이터베이스를 지탱하는 기술] 1장: 데이터베이스가 없으면 무엇이 곤란한가? (0) | 2022.11.09 |