
변수 (Variable)
컴퓨터 언어에서 변수(variable)란, 값을 저장할 수 있는 메모리상의 공간을 의미한다. 좀 더 쉽게 말해 변수란 단 하나의 값을 저장할 수 있는 공간이라고 할 수 있다.
변수 선언 및 초기화
변수를 선언(declaration)할 때는 변수의 타입과 이름을 함께 써주어야 한다. 변수타입은 변수에 담을 값의 종류와 범위를 충분히 고려하여 결정해야 한다. 또한, 변수를 사용하기에 앞서 적절한 값을 저장해주는 것이 필요하다. 이를 변수의 초기화(initialization)라고 한다.
이렇게 변수를 먼저 선언하고 후에 초기화 할 수 있고,
int num;
num = 10;선언과 동시에 초기화를 할 수도 있다.
int num = 10;타입이 동일한 여러 변수를 동시에 선언하거나 초기화하는 것도 가능하다.
int a, b;
int x=0, y=0;
// 위의 코드는 아래와 동일하다.
int a;
int b;
int x=0;
int y=0;
명명 규칙
- 대소문자가 구분되며 길이에 제한이 없다.
- 예약어를 사용해서는 안 된다.
- 숫자로 시작해서는 안 된다.
- 특수문자는 '_'와 '$'만을 허용한다.
예약어(reserved word)는 키워드(keyword)라고도 하는데, 프로그래밍 언어에서 이미 문법적인 용도로 사용되고 있기 때문에 식별자로 사용할 수 없는 단어들을 의미한다.
자바 예약어 리스트
| abstract | assert | boolean | break | byte | case |
| catch | char | class | const | continue | default |
| double | do | else | enum | extends | false |
| final | finally | float | for | goto | if |
| implements | import | instanceof | int | interface | long |
| native | new | null | package | private | protected |
| public | return | short | static | strictfp | super |
| switch | synchronized | this | throw | throws | transient |
| true | try | void | volatile | while |
암묵적 명명 규칙
명명 규칙 외에도 가독성을 높이기 위한 암묵적 규칙이 있다. 이 규칙을 지키지 않았다고 해서 에러가 발생하는 것은 아니지만, 반드시 지키도록 하자.
- 클래스 이름의 첫 글자는 항상 대문자로 한다.
- 변수와 메서드의 이름의 첫 글자는 항상 소문자로 한다.
- 여러 단어로 이루어진 이름은 단어의 첫 글자를 대문자로 한다.
- lastIndexOf, StringBuffer, ...
- 상수의 이름은 모두 대문자로 한다. 여러 단어로 이루어진 경우 '_'로 구분한다.
- PI, MAX_NUMBER, ...
변수의 타입 (Type)
모든 변수에는 타입(자료형)이 있으며 변수의 타입에 따라 저장할 수 있는 값의 종류와 범위가 달라진다. 변수의 타입은 크게 기본형(Primitive type) 과 참조형(Reference Type) 2가지로 나눌 수 있다.
기본형(Primitive type)
- 계산을 위한 실제 값을 저장하는 타입으로, 자바는 기본적으로 8개의 기본형을 제공한다.
- 기본형 변수는 실제 값(data)을 저장한다. 여기서 실제 값은 리터럴을 의미한다.
리터럴(literal)이란 소스 코드의 고정된 값을 대표하는 용어다.
리터럴은 일종의 값이다. true, false, 10, 11.1, a 등 이런 값 자체를 리터럴이라고 한다.
기본형에는 모두 8개의 타입이 있으며, 크게 논리형/정수형/실수형/문자형 4가지로 구분된다.
표로 정리하자면 다음과 같다.
| 구분 | 타입 | 메모리 크기 | 기본 값 | 표현 범위 |
| 논리형 | boolean | 1 byte | false | true, false |
| 정수형 | byte | 1 byte | 0 | -128 ~ 127 |
| short | 2 byte | 0 | -32,768 ~ 32767 | |
| int | 4 byte | 0 | -2,147,483,648 ~ 2,147,483,647 | |
| long | 8 byte | 0L | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | |
| 실수형 | float | 4 byte | 0.0F | (3.4 X 10^-38) ~ (3.4 X 10^38) 의 근사값 |
| double | 8 byte | 0.0 | (1.7 X 10^-308) ~ (1.7 X 10^308) 의 근사값 | |
| 문자형 | char | 2 byte (유니코드) | '\u0000' | 0 ~ 65,535 |
참조형(Reference Type)
- 참조형은 8개의 기본형을 제외한 나머지 타입으로, 객체의 주소를 저장한다.
- 이때 참조형은 null 또는 실제로 값이 저장되어 있는 주소를 값으로 가진다.
형변환 (타입 변환)
변수나 리터럴의 타입을 다른 타입으로 바꾸는 것을 형변환(type conversion)이라고 한다.
8개의 기본형 중에서 boolean을 제외한 나머지 7개의 기본형 간에는 서로 형변환이 가능하다. 다음과 같이 말이다.
| 변환 | 수식 | 결과 |
| int -> char | (char) 65 | 'A' |
| char -> int | (int) 'A' | 65 |
| float -> int | (int) 1.6f | 1 |
| int -> float | (float) 10 | 10.0f |
원칙적으로는 모든 형변환에 위의 표처럼 캐스트 연산자()가 이용되어야 하지만, 표현 범위가 작은 타입에서 큰 타입으로의 변환은 데이터의 손실이 없으므로 캐스트 연산자를 생략하는 것을 허용한다. 이처럼 캐스트 연산자를 생략한 경우엔 JVM 내부(컴파일러)에서 자동적으로 형변환이 수행된다.
반면 크기가 큰 타입에서 작은 타입으로의 변환은 값이 손실될 가능성(possible loss of precision)이 있으므로, JVM이 자동적으로 형변환을 하지 않고 사용자에게 캐스트 연산자를 이용하여 명시적으로 형변환을 하도록 강요한다. 만약 이러한 경우에 캐스트 연산자를 사용하지 않고 형변환을 시도하면 에러가 발생한다.
이렇게 말만 들으면 잘 와닿지 않을 수 있기 때문에, 예시를 통해 설명하고자 한다. 한 번 탁자 위에 500ml 물병과 1L 물병에 물이 가득 차있다고 상상해보자. 500ml 물병에 있는 물을 1L 물병으로 옮길 땐 아무 문제가 없다. 하지만 1L 물병에 있는 물을 500ml 물병으로 옮기면 물이 넘쳐서 흐를 것이다. 따라서 1L의 물 중 500ml는 없어지게 된다.
여기서 물은 데이터(리터럴), 물병은 변수(타입)과 대응된다. 이렇게 생각해보면 물이 넘쳐 흘러서 유실되는 상황을 자연스럽게 오버플로우에 의한 데이터 손실로 연결지어볼 수 있을 것이다.
묵시적 형변환 (타입 프로모션)
- 대입 연산이나 산술 연산에서 컴파일러가 자동으로 수행해주는 형변환
- 데이터의 손실이 발생하는 대입 연산은 허용되지 않고, 에러가 발생함
- 이를 타입 프로모션, 자동 형변환이나 암묵적 형변환이라고도 한다.
명시적 형변환 (캐스팅)
- 표현 범위가 더 큰 타입을 작은 타입으로 바꿀 때에 사용자가 캐스트 연산자를 사용하여 강제적으로 수행하는 형변환
- 이를 캐스팅, 혹은 강제 형변환 이라고도 한다.
묵시적 형변환과 명시적 형변환의 예시는 꼭 한 번 볼 필요가 있다고 생각해서 링크를 올려둔다.
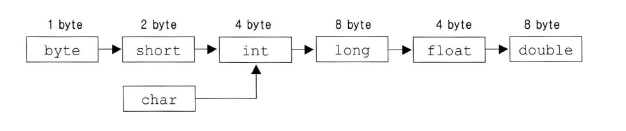
위 그림은 형변환이 가능한 7개의 기본형을 왼쪽부터 오른쪽으로 크기가 작은 타입부터 크기가 큰 타입의 순서로 나열한 것이다. 화살표 방향으로의 변환은 캐스트 연산자를 사용하지 않아도 자동적으로 형변환이 이루어지는 반면, 반대 방향으로의 변환은 반드시 캐스팅 연산자를 이용한 명시적 형변환이 이루어져야 한다.
보통 타입의 크기가 클수록 값의 표현범위가 크지만, 실수형은 정수형과 값을 표현하는 방식이 다르기 때문에 같은 크기일지라도 실수형이 정수형보다 훨씬 더 큰 표현 범위를 가진다. 따라서 위 그림 상에서 float와 double이 같은 크기인 int와 long보다 오른쪽에 위치한다.
char과 short은 크기가 동일하지만, char의 범위는 0 ~ 65,535이고 short의 범위는 -32,768 ~ 32767이므로 둘 중 어느쪽으로의 형변환도 데이터 손실이 발생할 수 있어서 자동적으로 형변환이 수행될 수 없다.
형변환 규칙
- boolean을 제외한 나머지 7개의 기본형은 서로 형변환이 가능하다.
- 기본형과 참조형은 서로 형변환할 수 없다.
- 서로 다른 타입의 변수간의 연산은 형변환을 하는 것이 원칙이지만, 값의 범위가 작은 타입에서 큰 타입으로의 형변환은 생략할 수 있다.
배열 (Array)
같은 타입의 여러 변수를 하나의 묶음으로 다루는 것을 배열이라고 한다.
배열의 선언
배열(1차원 배열)을 선언하는 방법은 다음과 같다. 원하는 타입의 변수를 선언하고 타입 또는 변수에 대괄호를 붙이면 된다. 가능하면 전자를 선택하도록 하자.
| 선언방법 | 선언 예 |
| 타입[] 변수이름; | int[] score; String[] name; |
| 타입 변수이름[]; | int score[]; String name[]; |
배열의 생성
위에서 배열을 선언한 행위는 단지 생성된 배열을 다루기 위한 참조변수를 위한 공간이 만들어진 것에 불과하다. 배열을 생성해야만 비로소 데이터를 저장할 수 있는 공간이 만들어진다. 배열을 생성하기 위해선 연산자 'new'와 함께 배열의 타입과 크기를 지정해주어야 한다.
int[] score; // 배열의 선언 (참조변수 선언)
score = new int[5] // 배열의 생성 (5개의 int값을 저장할 수 있는 공간 생성)
int[] score = new int[5] // 선언과 생성을 동시에
배열의 선언과 생성과정을 그림으로 살펴보면 다음과 같다.
1. int[] score;
int형 배열 참조변수 score를 선언한다. 데이터를 저장할 수 있는 공간은 아직 마련되지 않았다.

2. score = new int[5];
new 연산자에 의해서 메모리의 빈 공간에 5개의 int형 데이터를 저장할 수 있는 공간이 마련된다. 이때 배열은 주소 0x100번지에 생성되었다고 가정한다.

각 배열요소는 자동적으로 int형의 기본값인 0으로 초기화된다.

할당 연산자(=)에 의해 배열의 주소가 int형 배열 참조변수 score에 저장된다.

배열의 타입에 따른 기본값은 다음과 같다.
| 타입 | 기본값 |
| boolean | false |
| char | '\u0000' |
| byte, short, int | 0 |
| long | 0L |
| float | 0.0F |
| double | 0.0 또는 0.0D |
| 배열, 인스턴스 등의 참조변수 | null |
배열의 초기화
1차원 배열은 다음과 같이 초기화할 수 있다. 이 방법 외에도 반복문을 이용한 초기화 방법도 존재한다.
| 선언방법 | 선언 예 |
| 1. 배열이름[인덱스] = 배열요소; | score[0] = 1; name[0] = "Kim"; |
| 2. 타입[] 배열이름 = {배열요소1, 배열요소2, ...}; | int[] score = {70, 90, 80}; String[] name = {"Kim", "Park", "Lee"}; |
| 3. 타입[] 배열이름 = new 타입[]{배열요소1, 배열요소2, ...}; | int[] score = new int[]{70, 90, 80}; String[] name = new String[] {"Kim", "Park", "Lee"}; |
자세한 예시를 살펴보자
int[] score1 = {70, 90, 80}; // 배열의 선언과 동시에 초기화할 수 있음.
int[] score2 = new int[]{70, 90, 80}; // 배열의 선언과 동시에 초기화할 수 있음.
int[] score3;
// score3 = {70, 90, 80}; // 이미 선언된 배열을 이 방법으로 초기화하면 오류가 발생함.
int[] score4;
score4 = new int[]{70, 90, 80}; // 이미 선언된 배열은 이 방법으로만 초기화할 수 있음.
2차원 배열
2차원 배열은 배열의 요소로 1차원 배열을 가지는 배열이다.
다음의 경우 정수를 3개씩 담을 수 있는 일차원 배열이 2개 생성된다.
int[][] arr = new int[2][3];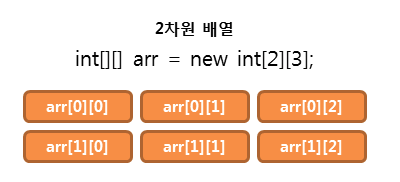
다음과 같이 가변 크기의 이차원 배열을 선언할 수 있고,
// 아래와 같이 선언하면 arr은 3개짜리 배열을 참조한다. 3개짜리 배열은 아직 참조하는 배열이 없다는 것을 의미.
int[][] arr = new int[3][];
arr[0] = new int[1]; //정수를 하나 담을 수 있는 배열을 생성해서 arr의 0 번째 인덱스가 참조한다.
arr[1] = new int[2]; //정수를 두개 담을 수 있는 배열을 생성해서 arr의 1 번째 인덱스가 참조한다.
arr[2] = new int[3]; //정수를 세개 담을 수 있는 배열을 생성해서 arr의 2 번째 인덱스가 참조한다
일차원 배열과 유사하게 선언과 동시에 초기화할 수 있다.
// 아래와 같이 선언할 경우 arr[0][0]는 1이다. arr[1][0]는 2이다.
int[][] arr = {{1}, {2,3}, {4,5,6}};
참고
자바의 정석(남궁성 저)
'프로그래밍 언어 > Java + Kotlin' 카테고리의 다른 글
| [Java] 스터디 6주차: 상속 (0) | 2021.07.07 |
|---|---|
| [Java] 스터디 5주차: 클래스 (0) | 2021.07.07 |
| [Java] 스터디 4주차: 제어문 (0) | 2021.06.24 |
| [Java] 스터디 3주차: 연산자 (0) | 2021.06.23 |
| [Java] 스터디 1주차: JVM은 무엇이며, 자바 프로그램은 어떻게 실행되는가 (0) | 2021.05.20 |